📑 논문 리뷰/CV
[AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
2022. 7. 13. 10:55
- -
CNN의 시작인 AlexNet
ImageNet Classification with Deep Convolutional Neural Networks
Abstract
- ImageNet LSVRC-2010의 test 데이터셋에서 top-1 error rate: 37.5%, top-5 error rate: 17.0% 달성
- ILSVRC-2012에서는 top-5 test error rate 15.3% 달성
- 신경망은 6천만 개의 파라미터와 65만 개의 뉴런을 가지고 있고,
max-pooling layer를 사용한 5개의 convolutional layer와 final 1000-way softmax를 사용한 3개의 fully-connected layer로 구성 - 학습을 빠르게 진행시키기 위해 non-saturating 뉴런과 convolution 가동에 매우 효율적인 GPU 사용
- fully-connected layer에서 overfitting을 줄이기 위해 dropout 사용
Dataset
- ILSVRC-2010에서만 test셋 label이 사용 가능해 대부분의 실험을 이 버전으로 사용
- ILSVRC-2012에도 모델을 등록해 이 버전에 대한 결과도 있지만 test셋 label은 사용할 수 없었음
- ImageNet에서는 두가지 error rate 사용
- 1) top-1 error rate: (정답 label) == (가장 probable 한 label)
- 2) top-5 error rate: (정답 label) in (상위 5 probable한 label)
- error rate 참고
- ImageNet은 다양한 해상도의 이미지들로 이루어져 있지만 논문에서 사용한 모델은 일정한 input 차원 수가 필요해
해상도가 고정된 256 × 256으로 down-sample 진행- 직사각형 이미지가 주어지면 먼저 짧은 변의 길이가 256이 되도록 이미지의 크기를 조정한 다음,
그 조정된 이미지에서 중앙의 256x256 패치를 잘라냄
- 직사각형 이미지가 주어지면 먼저 짧은 변의 길이가 256이 되도록 이미지의 크기를 조정한 다음,
- train셋의 각 픽셀에 mean activity를 빼는 것을 제외한 다른 전처리는 진행하지 않음
- 픽셀의 raw RGB value를 가지고 network를 훈련시킴
Architecture

5개의 convolutional layer와 3개의 fully-connected layer로 총 8개의 layer로 구성
ReLU Nonlinearity
- 보통 뉴런의 output은 tanh나 sigmoid를 거치는데
- tanh: $f(x) = tanh(x)$
- sigmoid: $f(x) = (1 + e^−x)^−1$
- 이러한 saturating nonlinearity는 gradient descent를 사용할 때 학습 속도가 non-saturating nonlinearity보다 매우 느림
- 따라서 논문에서는 non-saturating nonlinearity로 ReLU를 사용
- $f(x) = max(0, x)$

- tanh(점선)를 사용했을 때보다 ReLU를 사용했을 때 6배 빨리 training error rate 0.25 달성
-> 수렴 속도가 개선됐다
Training on Multiple GPUs
- 하나의 GTX 580 GPU는 메모리가 3GB이기 때문에 논문에서는 net을 2개의 GPU에 나눠서 진행
- 논문에서 적용한 병렬화 방식은 기본적으로 kernel(또는 뉴런)의 절반을 각 GPU에 배치하고, 추가적으로 GPU들끼리 특정 layer에서만 전달하도록 함
- 예를 들어, layer 3의 kernel들은 layer 2의 모든 kernel map으로부터 입력(input)을 받아오지만, layer 4의 kernel들은 같은 GPU에 있는 layer 3의 kernel map으로부터만 입력 받음
- 연결 패턴을 선택하는 것은 cross-validation의 문제이지만, 이를 통해 전달량이 계산량의 허용 가능한 부분이 될 때까지 전달량을 정밀하게 조정할 수 있음
- 그에 따른 아키텍처가 columnar CNN의 아키텍처와 다소 유사하지만 논문의 column들은 독립적이지 않다는 점이 다름
- 하나의 GPU에서 훈련된 각 convolutional layer의 kernel 수가 절반인 net와 비교했을 때, top-1과 top-5 error rate를 각각 1.7%, 1.2% 줄임
- 2개의 GPU를 사용한 net이 하나의 GPU를 사용한 net보다 학습 시간이 조금 더 짧았음
Local Response Normalization
- ReLU는 saturating을 방지하기 위한 input normalization이 필요하지 않다는 속성을 가짐
- 그러나 논문에서는 local normalization이 generalization에 도움이 된다는 것을 발견함

- $a^i_{x,y}$: (x, y) 위치에 커널 i kernel $i$를 적용한 다음 ReLU nonlinearity (비선형성)을 적용해 계산된 뉴런의 활동
- response-normalized 활동인 $b^i_{x,y}$ 는 위의 식으로 표현됨
- sum은 동일한 공간 위치에 있는 n개의 인접한 kernel map들에서 이루어짐
- $N$: layer의 총 kernel 수
- kernel map의 순서는 임의적이며 학습이 시작되기 전에 정해짐
- 이러한 종류의 response normalization은 실제 뉴런에서 발견되는 유형에서 영감을 받은 lateral inhibition을 구현한 형태
- 다른 kernel을 사용해 계산된 뉴런 output들 간에 경쟁을 일으킴
- 상수 $k$, $n$, $α$, $β$는 validation셋을 사용해 결정되는 하이퍼 파라미터로, 논문에서는 $k = 2$, $n = 5$, $α = 10^−4$ (=0.0001), $β = 0.75$ 로 설정
- 특정 layer들에서 ReLU nonlinearity를 적용한 후 이 normalization을 적용함
- Response normalization은 top-1과 top-5 error rate를 각각 1.4%, 1.2% 감소시킴
- CIFAR-10 데이터 셋에서도 이 방식의 효과를 확인함
- four-layer CNN의 test error rate이 normalization을 적용하지 않았을 때는 13%, 적용했을 때는 11%를 달성
Overlapping Pooling
- 전통적으로, pooling unit은 겹치지 않음
- pooling layer의 kernel 사이즈가 $z$, stride는 $s$라고 한다면
- $s = z$ 로 설정 -> CNN에 일반적으로 사용되는 전통적인 local pooling
- $s < z$ 로 설정 -> overlapping pooling
- => stride를 kernel 사이즈와 같게 설정하면 보통의 local pooling, stride를 kernel 사이즈보다 작게 설정하면 overlapping pooling
- 논문에서는 $s = 2$, $z = 3$으로 사용
- => stride = 2, kernel size = $3 × 3$
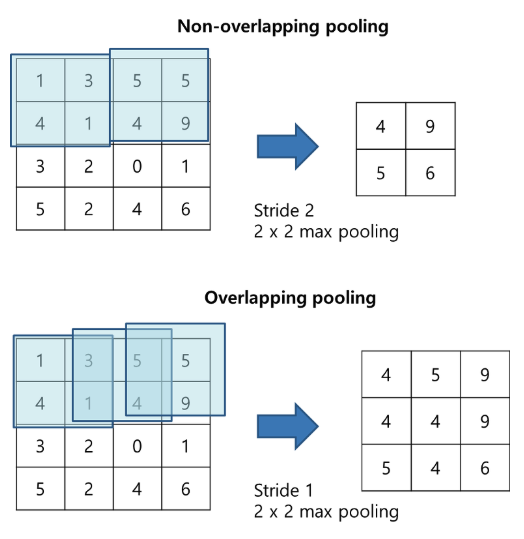
- 동일한 차원의 output을 생성하는 $s = 2, z = 2$의 non-overlapping pooling과 비교했을 때, overlapping pooling을 사용한 방식이 top-1 error rate: 0.4%, top-5 error rate: 0.3%로 감소시킴
- 학습하는 동안 overlapping pooling을 사용한 모델들에서 overfit이 덜 발생함
Overall Architecture

- AlexNet의 구조는 위/아래로 구분되어 있는데 이는 2개의 GPU를 병렬적으로 사용하기 위함
- 마지막 fully-connected layer의 output은 1000개의 클래스로 분류하는 1000-way softmax로 전달됨
- 2, 4, 5번째 conv layer의 kernel은 동일한 GPU에 있는 이전 layer의 kernel map에만 연결됨
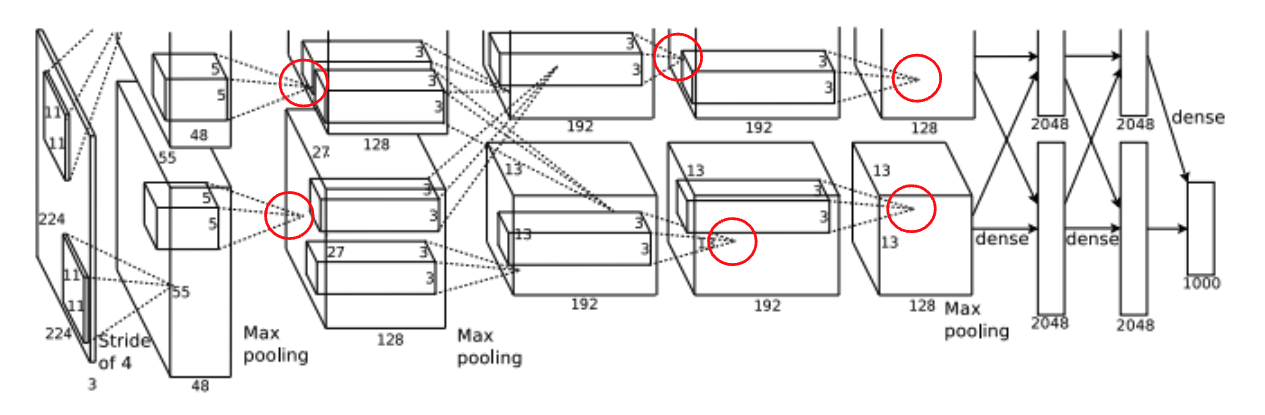
- 3번째 conv layer의 kernel은 2번째 layer의 모든 kernel map에 연결됨

- fully-connected layer의 뉴런은 이전 layer의 모든 뉴런과 연결됨
- Local Response Normalization이 1번째와 2번째 conv layer에서 일어남
- Max-pooling layer는 Local Response Normalization을 적용했던 1번째와 2번째 conv layer과 5번째 conv layer에서 일어남
- ReLU non-linearity는 모든 conv layer와 fully-connected layer의 output에 적용됨
Conv layer 1
- input image = $224×224×3$
- AlexNet은 RGB 3가지 색상을 가지는 Image를 input으로 사용. 그래서 이미지의 depth가 3이고, 이를 convolution 하기 위해 filter의 depth도 3이 됨
- kernel = 96
- kernel size = $11×11×3$
- stride = 4
Conv layer 2
- input = Local Response Normalization과 pooling이 적용된 conv layer 1의 output
- kernel = 256
- kernel size = $5 × 5 × 48$
Conv layer 3
- input = Local Response Normalization과 pooling이 적용된 conv layer 2의 output
- kernel = 384
- kernel size = $3 × 3 × 256$
Conv layer 4
- kernel = 384
- kernel size = $3 × 3 × 192$
Conv layer 5
- kernel = 256
- kernel size = $3 × 3 × 192$
- 3, 4, 5번째 conv layer는 pooling이나 normalization 없이 연결됨
fully-connected layers
- 각각 4096 개의 뉴런을 가짐
cf) input image = $224×224×3$ or input image = $227×227×3$


- 논문에서는 input이 $224×224$으로 나오는데 위의 두 이미지에서는 $227×227$이라고 설명되어 있음
- 논문에 설정된 stride와 padding을 고려했을 때, 여러 layer를 거쳐 $13×13$으로 도달하려면 $227×227$이 맞다고 함
- => 논문의 그림이 잘못된 것
Reducing Overfitting
overfitting을 줄이기 위해 Data Augmentation과 Dropout 사용
Data Augmentation
- 이미지 데이터에 대한 overfitting을 줄이는 가장 쉽고 일반적인 방법은 label-preserving transformations를 사용해 데이터셋을 인위적으로 늘리는 것
- label-preserving transformation
- : 원본 데이터(label)의 특성을 그대로 보존(preserving)하면서 변환(transformation)하는 것
- 상하반전 같은 기법을 사용할 때, 의미가 완전히 바뀔 수 있기 때문

- 논문에서는 두 가지 형태의 data augmentation을 사용했는데 두 가지 모두 아주 적은 계산으로 원본 이미지에서 변환된 이미지를 생성할 수 있으므로 변환된 이미지를 디스크에 저장할 필요가 없게 함
- 변환된 이미지들은 GPU가 이미지의 이전 batch에서 학습하는 동안 CPU에서 Python 코드로 생성되게 함. 따라서 이러한 data augmentation 방식은 사실상 계산이 필요하지 않음
1) 좌우 반전 (horizontal reflection)
- Training
- $256 × 256$의 원본 이미지 중 $224 × 224$ 크기의 이미지를 무작위로 추출, 추출된 이미지를 좌우 반전시켜 이 추출된 이미지들을 학습시킴
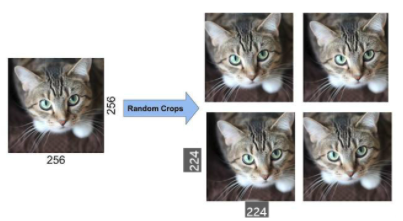
- 이 방법으로 1장의 이미지에서 $32 × 32 × 2 = 1024 × 2 = 2048$ 개의 다른 이미지를 얻을 수 있게 됨
- Test
- 5개의 $224 × 224$ 이미지(4개의 모서리와 중앙에서 추출한 이미지)와 이들을 각각 좌우 반전한 이미지를 추출
- => 총 10개의 이미지


- 이렇게 추출한 10개의 이미지에 대해 softmax layer가 만든 예측을 평균화해서 예측함
2) 훈련 이미지의 RGB 채널 값 변경
- 원래 픽셀 값 + 이미지의 RGB 픽셀에 대한 주성분 분석(PCA)한 값 X (평균: 0, 표준편차: 0.1인 Gaussian에서 추출한) 랜덤 변수
- 이 방식은 원본 이미지의 중요한 속성, 즉 물체의 identity가 빛의 강도와 색상의 변화에 변하지 않는다는 점을 대략적으로 포착함
- 이 방식으로 top-1 error rate를 1% 이상 감소시킴
Dropout
- dropout: iteration 마다 layer 노드 중 일부를 사용하지 않으면서 학습을 진행하는 방법

- 여러 개의 모델을 만드는 대신, 모델 결합(model combination)에 의한 투표 효과(Voting)과 비슷한 효과를 내기 위해 학습이 진행되는 동안 무작위로 일부 뉴런을 생략함
- 생략된 뉴런의 조합만큼 지수함수적으로 다양한 모델을 학습시키는 것과 마찬가지이기 때문에 모델 결합의 효과를 누릴 수 있음
- 생략된 모델들이 모두 파라미터를 공유하고 있기 때문에 모두 각각의 뉴런들이 존속할(dropout 하지 않을) 확률을 각각의 가중치에 곱해주는 형태가 됨
- 1, 2번째 fully-connected layer에 dropout을 적용시킴
- Dropout(0.5) -> 50%만 사용한다
- dropout은 수렴에 필요한 iteration의 수를 대략 2배 증가시킴
Details of learning
- 학습 시, batch size = 128, momentum = 0.9, weight decay = 0.0005로 확률적 경사 하강법(SGD, stochastic gradient descent) 적용
- 여기서 weight decay(가중치 감소)는 그저 regularizer가 아니라 모델의 training error를 줄임
- 표준 편차가 0.01인 zero-mean Gaussian distribution으로부터 각 layer의 가중치를 초기화함
- 2번째, 4번째, 5번째 conv layer와 fully-connected hidden layer에서 뉴런 편향을 상수 1로 초기화함
- 이 초기화는 ReLU에 positive input을 제공해 학습의 초기 단계를 가속화함
- 남아있는 layer에는 뉴런 편향을 상수 0으로 초기화함
- 논문에서는 모든 layer에 대해 동일한 학습률을 적용했고, 학습 내내 수동으로 조정함
- validation error rate가 현재의 학습률로 개선되지 않을 때, 10으로 나눈 학습률을 적용함
- 학습률은 0.01로 초기화했고, 학습 종료 전까지 3번 감소함
- 120만 개의 이미지 train셋을 대략 90 cycle 동안 학습시켰고, 이는 2개의 NVIDIA GTX 580 3GB GPU로 5~6일이 소요됨
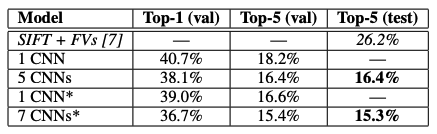
Results
- ILSVRC-2010의 test셋에 대한 결과

- ILSVRC-2012의 val셋과 test셋에 대한 결과
Qualitative Evaluations

- 96개의 kernel 중 위쪽의 48개의 kernel은 GPU-1에서, 아래쪽의 kernel 48개는 GPU-2에서 학습됨
- GPU-1에서는 주로 컬러와 상관 없는 정보를 추출하기 위한 kernel이 학습되고, GPU-2에서는 주로 컬러와 관련된 정보를 추출하기 위한 kernel이 학습됨

- 8개의 ILSVRC-2010 test 이미지들과 모델이 예측한 top-5 레이블을 나타낸 것
- 올바른 레이블이 각 이미지 아래에 적혀있고, 올바른 레이블에 할당된 확률도 빨간색 막대로 표시되어있음 (top 5에 있는 경우)
- 왼쪽 상단의 mite(진드기) 이미지와 같이 중심에서 벗어난 물체도 잘 인식된 것으로 나타남
- grille과 cherry의 경우, 사진의 의도된 초점에 대한 모호성이 존재함
- 하지만 예측이 틀린 경우에도 보기에 따라 예측이 가능한 답변을 반환했다고 볼 수 있음

- 맨 왼쪽의 첫번째 칼럼은 5개의 ILSVRC-2010 test 이미지
- 나머지 칼럼들은 5개의 test 이미지에 각각 가장 비슷하다고 예측되는 6개의 training 이미지
- 강아지나 코끼리의 경우, 다양한 포즈로 나타남
Discussion
- 하나의 conv layer라도 제거되었을 때, 모델의 성능이 저하된다는 점이 주목할 만함
참고 자료
[DL - 논문 리뷰] ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
이번 포스팅에서는 AlexNet이라고 알려져 있는 Alex Krizhevsky가 2012년에 소개한 "ImageNet Classification with Deep Convolutional Neural Networks"를 읽고 정리해 보도록 하겠습니다. AlexNet은 ILSVRC-..
jjuon.tistory.com
[CNN 알고리즘들] AlexNet의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
https://learnopencv.com/understanding-alexnet/
Understanding AlexNet | LearnOpenCV #
Understand the AlexNet architecture that won the ImageNet Visual Recognition Challenge in 2012 and started the Deep Learning revolution.
learnopencv.com
https://oi.readthedocs.io/en/latest/computer_vision/cnn/alexnet.html
AlexNet — Organize everything I know documentation
AlexNet은 Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton의 논문 “ImageNet classification with deep convolution neural network”에서 제안한 모델이다. 또한, AlexNet은 ImageNet ILVRC-2010의 120만 개 이미지를 1000개의 Class로
oi.readthedocs.io
https://89douner.tistory.com/60?category=873854
6. AlexNet
안녕하세요~ 이제부터는 CNN이 발전해왔던 과정을 여러 모델을 통해 알려드릴까해요. 그래서 이번장에서는 그 첫 번째 모델이라 할 수 있는 AlexNet에 대해서 소개시켜드릴려고 합니다! AlexNet의 논
89douner.tistory.com
https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=laonple&logNo=220818841217
[Part Ⅵ. CNN 핵심 요소 기술] 2. Dropout [1] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic Segmentat...
blog.naver.com
Contents
소중한 공감 감사합니다 :)